
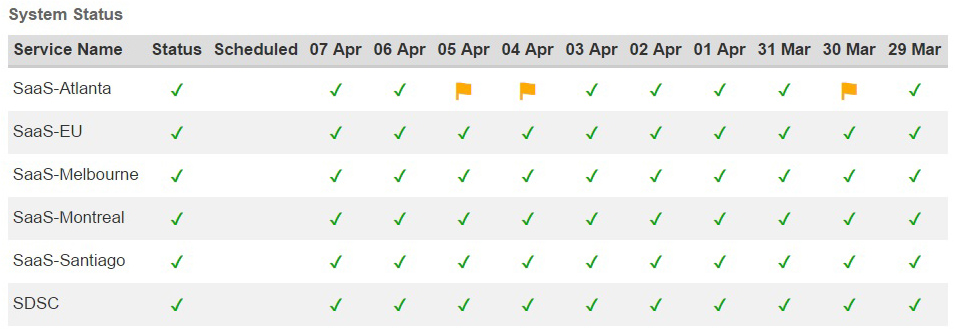
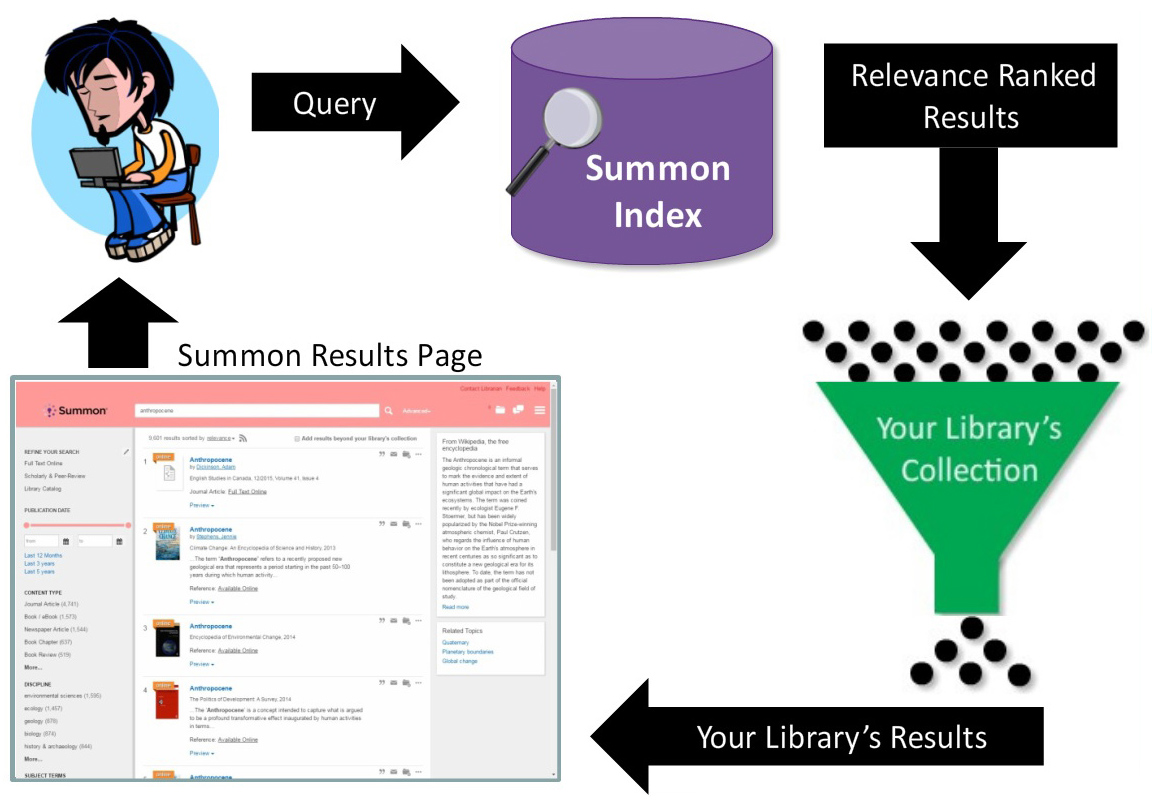
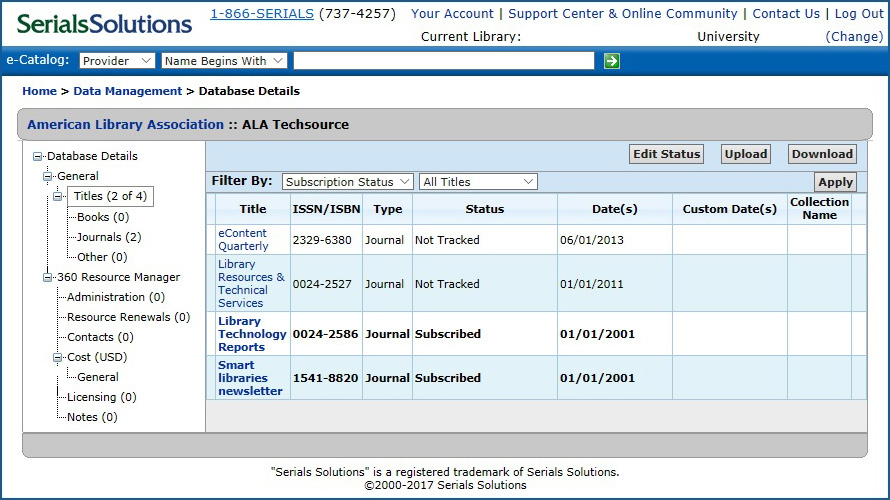
| A proxy server is a service that provides authentication and mediation between database or publisher websites and the end user by routing Internet traffic through its system. |
Why learn about proxy servers?
A proxy server is a service that libraries use to authenticate their users to provide access to many online databases and publisher websites. Using a proxy service allows library resource vendors to authenticate users from a single point-of-access regardless of where they are located, on-campus or from their home computer.
The Basics
For our examples, we’ll use the popular EZproxy product from OCLC.
Authentication
To avoid having to provide users with an individual or institutional login and password, most database and publisher websites authenticate users by IP address. Sometimes vendors will limit access to a range of IP addresses—on a single campus, for example. But for users outside of the physical campus, you must provide a known IP address (or set of IP addresses). This is accomplished by routing users through a proxy server so that the access requests come from its IP address(es) which are recognized by the vendor. The content is then returned to the proxy server and routed back to the original user.
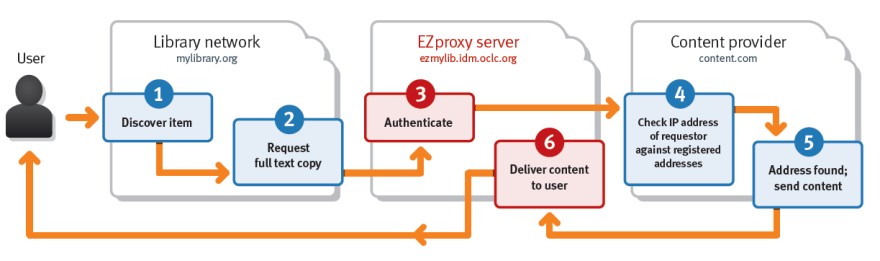
Because libraries can’t let everyone access their resources via EZproxy, they must authenticate their users before access. EZproxy allows user login itself, but EZproxy also provides a method of authentication using your institution’s single sign-on (SSO) server.
Resource Access
EZproxy is accessed using an HTTP request. To access a website via EZproxy, you must prepend the EZproxy server URL to the database or publisher’s website address. A typical EZproxy URL looks like this:
http://ezproxy.yourlib.org/login?url=
To this proxy URL, we add the URL for the website we wish to access through EZproxy. For example:
http://ezproxy.yourlib.org/login?url=http://www.credoreference.com
The above URL is referred to as a “pre-proxy” link. Once a website is accessed via EZproxy, the address changes to a “post-proxy” URL. For example:
http://search.credoreference.com.ezproxy.yourlib.org
As you perform a search or click on links on a database or publisher site, you are submitting your requests to your EZproxy server which passes them on to the original website. Data is returned to the EZproxy server which sends it back to your browser. That is why the post-proxy URL ends with .ezproxy.yourlib.org (ignoring the path).
You might notice some post-proxy URLs use hyphens instead of dots between parts of the original website’s address.
https://refworks-proquest-com.ezproxy.libproxy.db.erau.edu.
The short explanation is that the EZproxy server uses a wildcard security (SSL) certificate for *.ezproxy.yourlib.org which allows one subdomain before the EZproxy server domain (ezproxy.yourlib.org). The hyphens “trick” the server into seeing the original website as a single subdomain. This is done only for original websites that use HTTPS.
EZproxy Configuration
EZproxy has many settings that are configured during initial installation (using hyphens with HTTPS, for example). You also set the maximum number of virtual hosts (typically from 5,000 to 20,000).
For each resource you access through EZproxy, you must configure it separately in a block of code called a stanza. In the stanza for a database or publisher website you must specify at the minimum a Title (T) and starting URL (U). Other basic stanza directives are Host (H), HostJavaScript (HJ), Domain (D), and DomainJavaScript (DJ). Below is a basic database stanza:
Title SPIE Digital Library URL http://www.spiedigitallibrary.org DJ spiedigitallibrary.org
The Title directive is used to identify the resource (and is used for the link text on the default EZproxy list page). The URL is used to match the EZproxy request link with the appropriate stanza to apply. Once accessed, any further links on the resource site will be compared to any D or DJ lines and if there is a match, will be proxied and given access (including any JavaScript if a DJ line is encountered).
If a database or publisher website includes multiple domains or subdomains or uses both HTTP and HTTPS, you need to add Host (H) or HostJavaScript (HJ) directives to account for them. More advanced directives are used to manage website cookies, set domains that should never be proxied, find and replace HTML code, and many others. OCLC publishes an EZproxy Reference Manual to list these directives.
Here is a more advanced database stanza:
Option DomainCookieOnly Title Engineering Village URL http://www.engineeringvillage.com HJ https://www.engineeringvillage.com HJ engineeringvillage.com HJ www.engineeringvillage.com HJ www.engineeringvillage2.org HJ www.ei.org HJ acw.elsevier.com DJ ei.org DJ engineeringvillage.com DJ referexengineering.elsevier.com Option Cookie
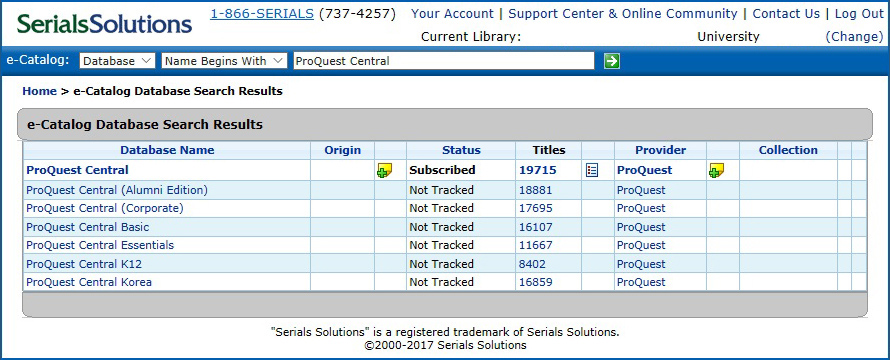
OCLC publishes a list of recommended database stanzas for many of the most popular databases. Of course, websites are frequently updated and these changes often require revised or completely new stanzas. These stanzas are found in the config.txt file.
Resources
Here are some resources to learn more about EZproxy.
- Learn EZproxy – OCLC’s official site with documents and links to the EZproxy community.
- EZproxy Frequently Asked Questions – Common answers for EZproxy administrators.


 In addition to bookmarking the above sites, follow your important library vendors on
In addition to bookmarking the above sites, follow your important library vendors on 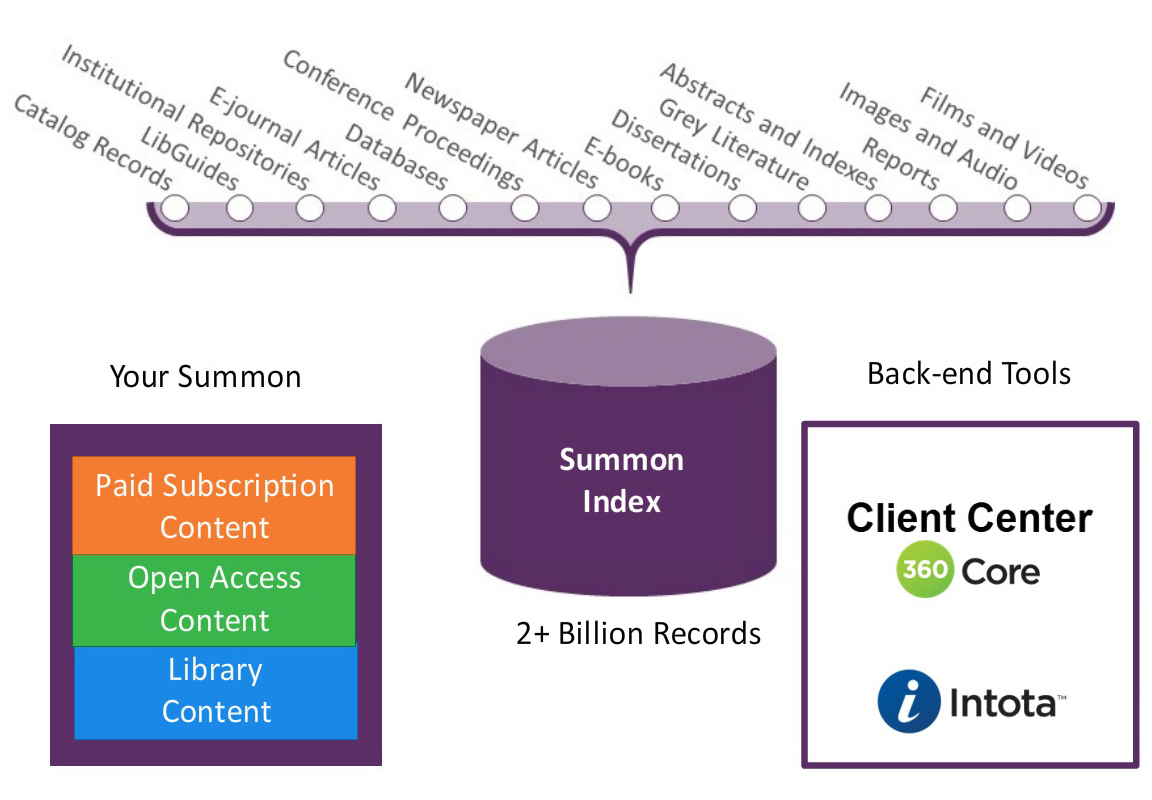
 “A white paper commissioned by the NISO Discovery to Delivery (D2D) Topic Committee” gives an overview of the current state of library discovery services and looks into how they might adapt to the future. Published in 2015.
“A white paper commissioned by the NISO Discovery to Delivery (D2D) Topic Committee” gives an overview of the current state of library discovery services and looks into how they might adapt to the future. Published in 2015. Part of the “Advances in Library and Information Science” (ALIS) series. This book is a collection of papers covering discovery UX, e-metrics, open source, digital libraries, and library usage studies. Published in 2016.
Part of the “Advances in Library and Information Science” (ALIS) series. This book is a collection of papers covering discovery UX, e-metrics, open source, digital libraries, and library usage studies. Published in 2016. No. 9 in the “Practical Guides for Librarians” series. From the publisher: this book is a “one-stop source for librarians seeking to evaluate, purchase, and implement a web-scale discovery service.” Published in 2014.
No. 9 in the “Practical Guides for Librarians” series. From the publisher: this book is a “one-stop source for librarians seeking to evaluate, purchase, and implement a web-scale discovery service.” Published in 2014. This title is actually an issue of Library Technology Reports from ALA Tech Source. The report covers the content, interface, and functionality of discovery services from the major vendors to help with evaluation. Possibly a bit dated now. Published in 2011.
This title is actually an issue of Library Technology Reports from ALA Tech Source. The report covers the content, interface, and functionality of discovery services from the major vendors to help with evaluation. Possibly a bit dated now. Published in 2011. A look at
A look at  Linked Data is a set of practices which involves the publishing, sharing, and connecting of related data across the Web in a structured format, preferably using an open access license.
Linked Data is a set of practices which involves the publishing, sharing, and connecting of related data across the Web in a structured format, preferably using an open access license. BIBFRAME is a bibliographic framework for the description of physical and online objects to make them accessible on the Web by using a standard Linked Data model. It is a replacement for MARC.
BIBFRAME is a bibliographic framework for the description of physical and online objects to make them accessible on the Web by using a standard Linked Data model. It is a replacement for MARC. Altmetrics are “alternative metrics” to measure the influence and reach of scholarly output on the Web through peer-review counts, influential news sites and blog posts, citation manager bookmarks such as Mendeley, Wikipedia citations, and social media mentions on sites such as Twitter and Facebook.
Altmetrics are “alternative metrics” to measure the influence and reach of scholarly output on the Web through peer-review counts, influential news sites and blog posts, citation manager bookmarks such as Mendeley, Wikipedia citations, and social media mentions on sites such as Twitter and Facebook.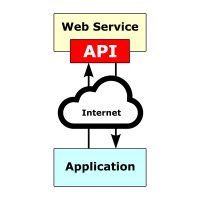 API stands for Application Programming Interface which allows external applications to access software or Web services data, in the latter case by using HTTP request messages, for recombination (mashup) or custom presentation by the external application.
API stands for Application Programming Interface which allows external applications to access software or Web services data, in the latter case by using HTTP request messages, for recombination (mashup) or custom presentation by the external application.