
| A Digital Object Identifier (DOI) is a unique and persistent identifier which provides a link to an object on the Internet via a registration and indexing service. |
Why learn about DOIs?
 DOIs are often used in citations and discovery services to provide permanent links to online articles, ebooks, images, reports, and other types of online objects. Publishers now regularly assign a DOI to each journal article or ebook (or ebook chapter) they publish. Many times, when a direct link or OpenURL lookup fails, an item still can be located using its published DOI. Even if an object changes location on the Internet, its DOI will remain the same (and point to the new location).
DOIs are often used in citations and discovery services to provide permanent links to online articles, ebooks, images, reports, and other types of online objects. Publishers now regularly assign a DOI to each journal article or ebook (or ebook chapter) they publish. Many times, when a direct link or OpenURL lookup fails, an item still can be located using its published DOI. Even if an object changes location on the Internet, its DOI will remain the same (and point to the new location).
The Basics
The Digital Object Identifier system is an ISO standard (ISO 26324) officially maintained by the International DOI Foundation (IDF). The IDF provides the infrastructure to support DOIs by governing independent DOI Registration Agencies. It was created in 1997 with DOI becoming a standard in 2012.
Note that according to the IDF, a DOI is a “digital identifier of an object” rather than an “identifier of a digital object”.
DOI Format
Each Digital Object Identifier has a unique alphanumeric string made up two parts:
{prefix}/{local name}
The prefix is a numeric string beginning with 10. and followed by several more numbers, usually four (ex. 10.1103). The prefix is assigned by a Registration Agency to a publisher, institution, organization, or other types of Registrant.
The local name (suffix) follows the forward slash and is a unique alphanumeric string (for that prefix). The local name for an object is chosen by the Registrant using whatever naming scheme they want
(ex. PhysRevLett.116.061102).
If you’re curious about why the DOI has its particular structure, see the Handle.Net Registry Technical Manual.
DOI URL
A DOI handle can be converted into a useful URL by adding it as a path after the domain https://doi.org.
So, for the previous prefix and local name (suffix) examples above, the full linkable URL would be:
https://doi.org/10.1103/PhysRevLett.116.061102
Note that older DOI URLs use the http://dx.doi.org format which was deprecated in 2016 (but is still supported).
DOI Uses
As stated, the Digital Object Identifier often points to digital content such as journal articles and ebooks (or individual chapters or even data). Because DOIs provide a permanent link to these scholarly works, they are now frequently included—and sometimes required by journal publishers—in citations. Of course, the various style guides have rules on how to format them in citations. Here is an example of an APA citation with a DOI:
 All of the style guides offer help for adding DOIs to citations. Major ones include:
All of the style guides offer help for adding DOIs to citations. Major ones include:
- APA Style Guide – What is a digital object identifier, or DOI?
- Chicago Manual of Style – Sample Citations: Journal Article
- MLA Style Center – Ask the MLA: DOI
Publisher sites and databases often include DOIs in the online article or ebook itself. This makes it easy to cite or to make a persistent link in a reading list. For example, if an article has a DOI, Elsevier displays it as a link after the title and author(s).
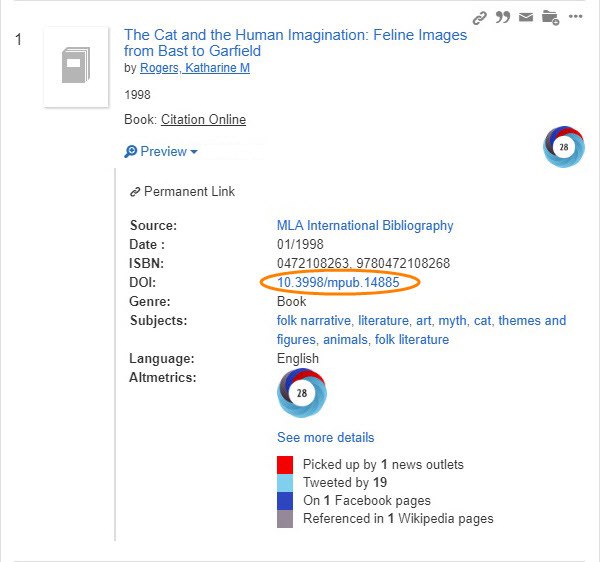
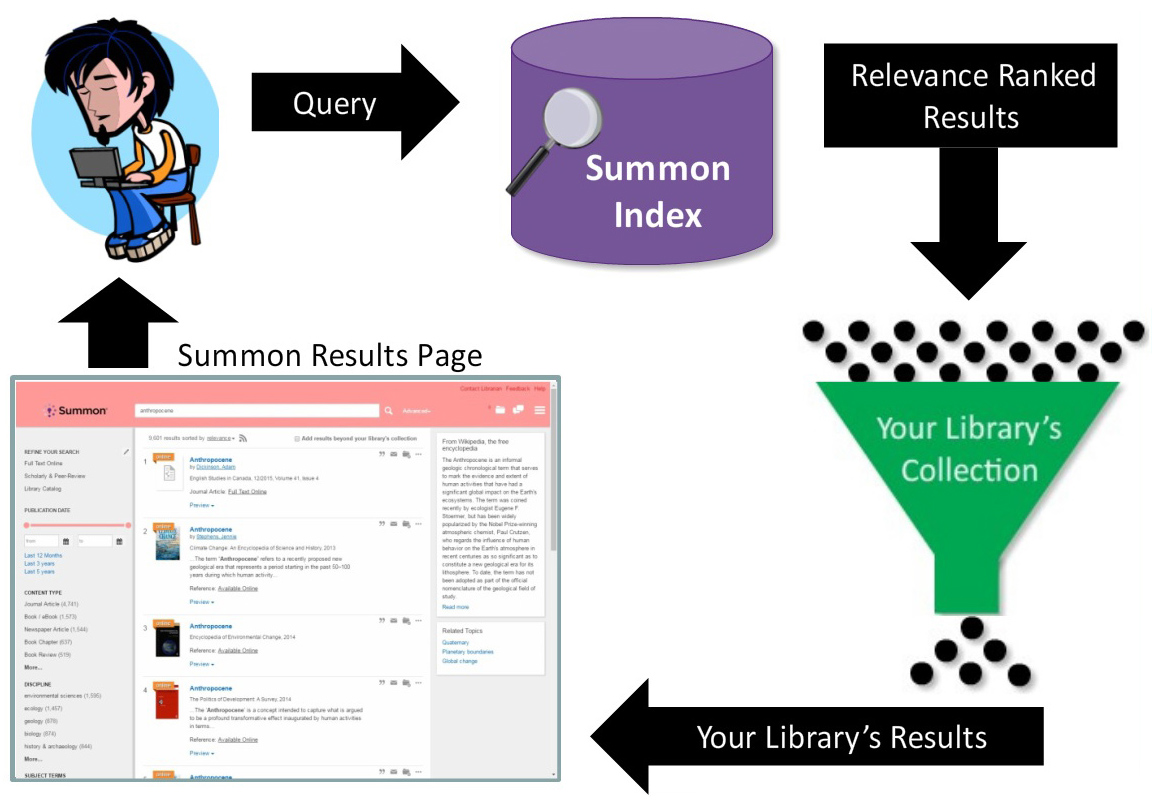
 Digital Object Identifiers are part of the metadata indexed in library discovery services. EBSCO Discovery Service, Primo, Sierra, Summon, and WorldCat Discovery all display a DOI field on search results or on item detail screens (if available). Sometimes they are links. Including the DOI is useful when the search result link is broken as it provides a secondary method for locating the resource. For example, Summon displays the item’s DOI as a link when you expand the “Preview” section.
Digital Object Identifiers are part of the metadata indexed in library discovery services. EBSCO Discovery Service, Primo, Sierra, Summon, and WorldCat Discovery all display a DOI field on search results or on item detail screens (if available). Sometimes they are links. Including the DOI is useful when the search result link is broken as it provides a secondary method for locating the resource. For example, Summon displays the item’s DOI as a link when you expand the “Preview” section.
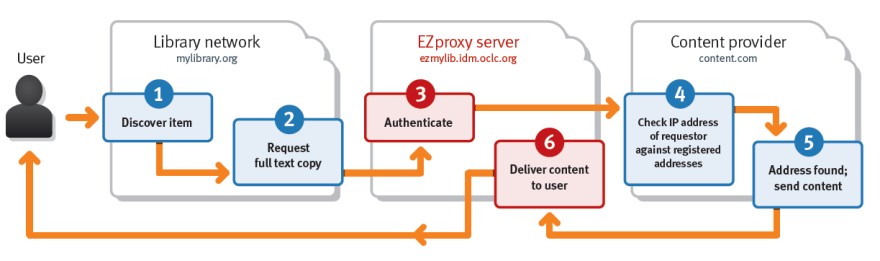
 DOI Registration
DOI Registration
For many years librarians and researchers have been using Digital Object Identifiers. More and more librarians are becoming the creators and maintainers of DOIs as yet another type of metadata to enhance discovery and access. As we have seen, DOI links point to a URL that serves as a central index and redirection service. DOI URLs are translated into the actual URL of the target object. So how does this index get built?
The central DOI index is maintained by several DOI Registration Agencies. The most important of these is Crossref. Publishers and other institutions become members and pay to create DOIs for their items. With the rise of university publishing and institutional repositories, more universities are enhancing their scholarly output with DOIs to aid in their discovery and sharing. Increasingly, librarians are assisting university faculty with creating DOIs as part of the publishing process. Cataloging and scholarly communications librarians are frequently tasked with creating and managing the DOIs for these repositories.
Resources
Here are official resources to learn about DOIs:
- DOI.org – Website of the International DOI Foundation (IDF).
- DOI Handbook – Official source of information about the DOI system.
- Driven by DOI – Watch videos and download brochures.
Library-related DOI registration agencies:
- Crossref – Popular DOI agency for scholarly publishing.
- DataCite – “[L]eading global provider of DOIs for research data.”
- mEDRA – Multilingual European Registration Agency.
Useful DOI tools:
- DOI Citation Formatter – Crosscite will format an entered DOI in one of hundreds of citation styles.
- DOI Resolver – Google Chrome extension to create links and citations from a DOI.
- Custom DOI resolver – Firefox extension to turn a non-linked DOI into a URL.
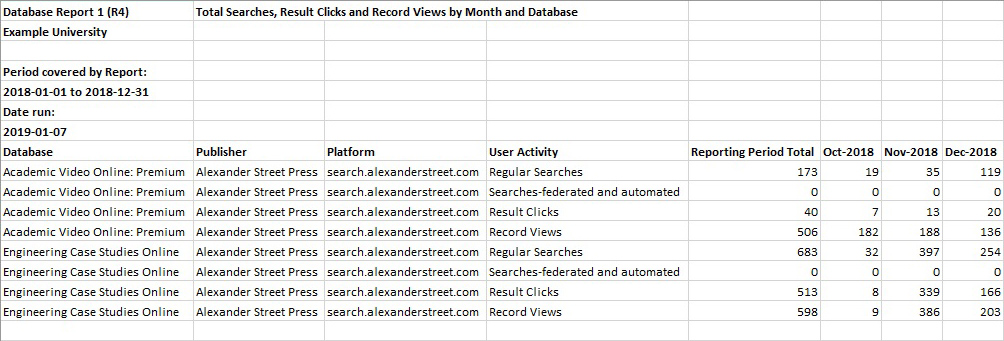
 There are four types of item-type usage reports each with their unique statistics:
There are four types of item-type usage reports each with their unique statistics:
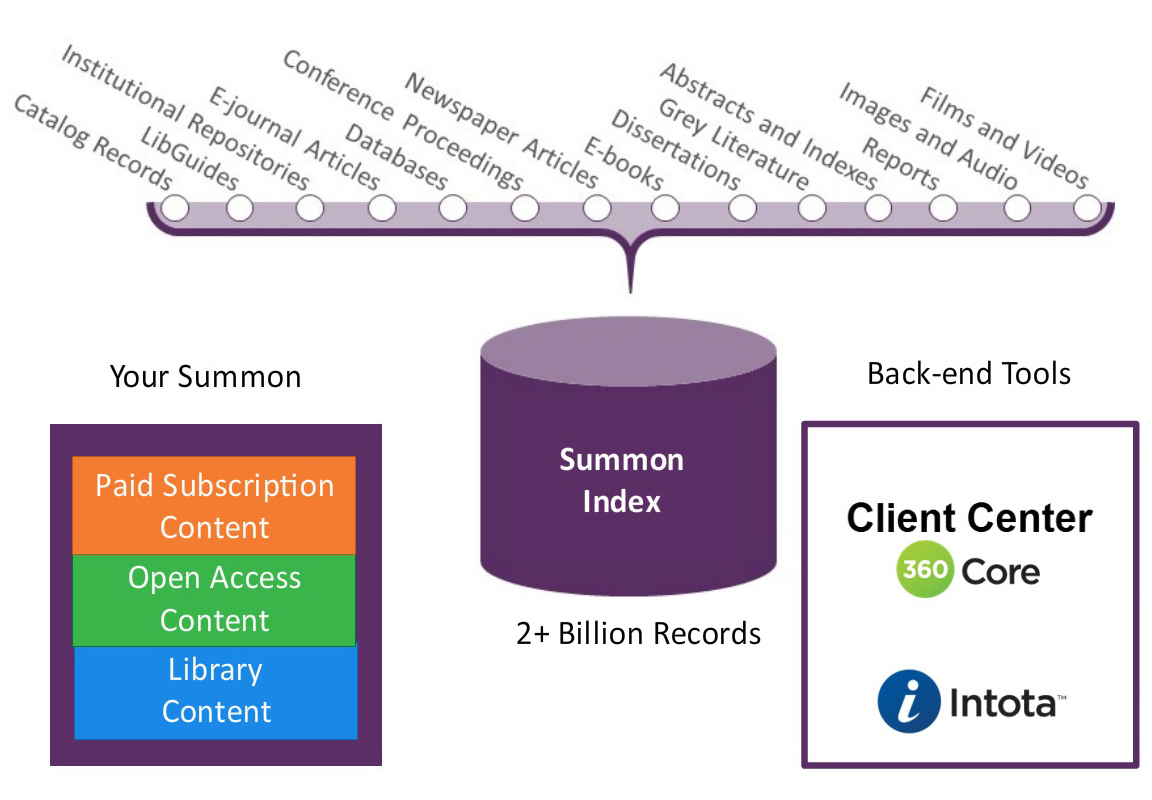
 “A white paper commissioned by the NISO Discovery to Delivery (D2D) Topic Committee” gives an overview of the current state of library discovery services and looks into how they might adapt to the future. Published in 2015.
“A white paper commissioned by the NISO Discovery to Delivery (D2D) Topic Committee” gives an overview of the current state of library discovery services and looks into how they might adapt to the future. Published in 2015. Part of the “Advances in Library and Information Science” (ALIS) series. This book is a collection of papers covering discovery UX, e-metrics, open source, digital libraries, and library usage studies. Published in 2016.
Part of the “Advances in Library and Information Science” (ALIS) series. This book is a collection of papers covering discovery UX, e-metrics, open source, digital libraries, and library usage studies. Published in 2016. No. 9 in the “Practical Guides for Librarians” series. From the publisher: this book is a “one-stop source for librarians seeking to evaluate, purchase, and implement a web-scale discovery service.” Published in 2014.
No. 9 in the “Practical Guides for Librarians” series. From the publisher: this book is a “one-stop source for librarians seeking to evaluate, purchase, and implement a web-scale discovery service.” Published in 2014. This title is actually an issue of Library Technology Reports from ALA Tech Source. The report covers the content, interface, and functionality of discovery services from the major vendors to help with evaluation. Possibly a bit dated now. Published in 2011.
This title is actually an issue of Library Technology Reports from ALA Tech Source. The report covers the content, interface, and functionality of discovery services from the major vendors to help with evaluation. Possibly a bit dated now. Published in 2011. Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) specifies how metadata is structured and presented for ingestion by external services, usually on the Internet. OAI-PMH metadata is encoded in extensible markup language (XML) format. OAI-PMH records are harvested using HTTP requests.
Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) specifies how metadata is structured and presented for ingestion by external services, usually on the Internet. OAI-PMH metadata is encoded in extensible markup language (XML) format. OAI-PMH records are harvested using HTTP requests.